Workload Optimization API for AI Systems
Unomiq helps with unit economics optimization across AI systems in production

Most AI systems don't fail technically, they fail economically
Unit economics are measured and understood post-hoc
It takes 3 to 9 months to move from pilot to production, only for economic issues to surface too late to correct.
40% of agentic AI systems are expected to be canceled due to escalating costs or unclear value.
88% of AI POCs never reach deployment because ROI can’t be measured with confidence.
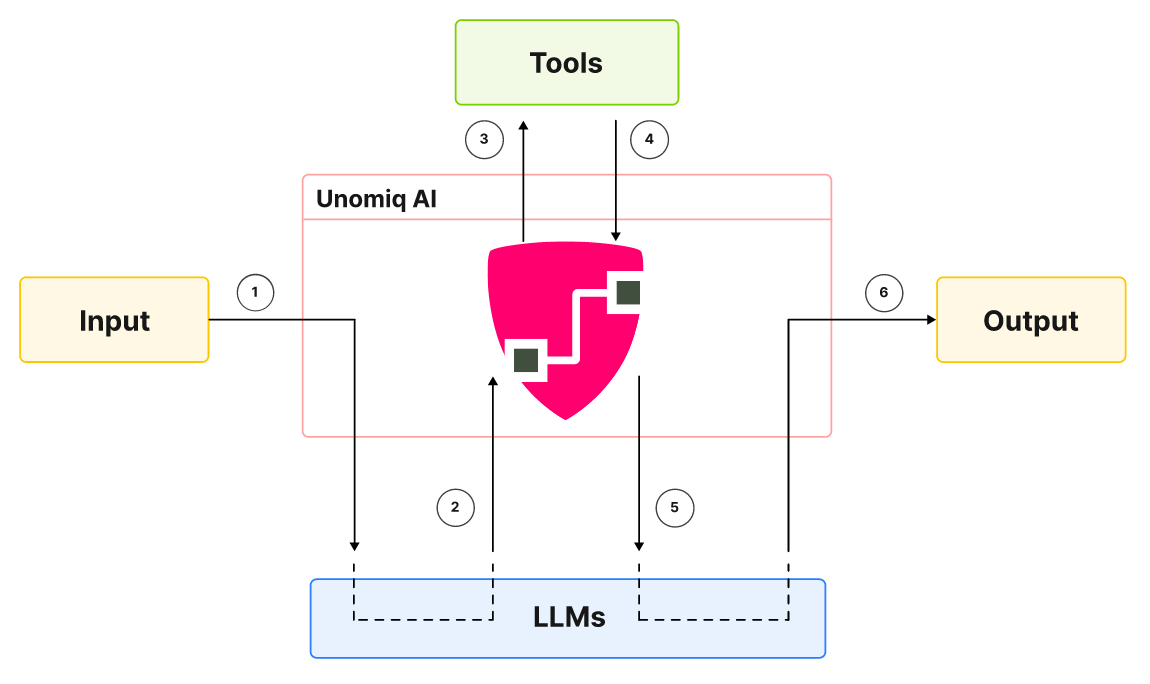
Not just a dashboard. API-first, outcome-ready.
Unomiq provides the embeddable economic layer that helps teams operating large-scale AI systems deliver scalable outcomes with confidence.
Understand the cause at runtime
Most teams try to understand unit economics from the bottom up: starting with infrastructure spend and stitching together billing data to infer insights after execution has already happened.
Unomiq takes a fundamentally different, top-down approach, starting at the application layer and using the trace as the fundamental unit of execution.
By observing and governing economic behavior at the trace level, teams can map cost and value directly to what the system is doing as it runs, making unit economics actionable at runtime.
Multi-level unit economics
Economic outcome only becomes auditable when units can be defined per customer, per application, per agent, or any other meaningful boundary.
Unomiq supports this flexibility by allowing you to define economics at the level where execution actually matters.
This means teams get precise cost attribution and can identify which units are profitable and which are not, and make faster, more confident decisions about scaling, pricing, and resource allocation.
Embed economic guardrails
Instead of relying on post-hoc analysis to catch runaway costs, Unomiq enables engineering teams to embed economic guardrails directly into their AI systems at the execution layer. These guardrails evaluate cost and value signals at runtime, giving systems the ability to self-regulate without manual intervention:
Short-circuit execution when marginal returns fall below defined thresholds
Degrade gracefully by switching to cheaper models or reducing scope when budget constraints are hit
Detect and break uncontrolled retry loops or recursive agent calls before they spiral


Fixed high capacity — wastes spend during off-peak hours
Optimize AI workloads automatically
AI request patterns are rarely uniform. Traffic spikes, off-peak lulls, and shifting workload compositions make static resource allocation a losing game — you either over-provision and overspend, or under-provision and breach SLAs. Unomiq profiles your AI workloads continuously and scales resources to match actual demand:
Profile LLM calls, vector store, memory, tool compute, and retrieval in real time
Pre-scale resources before traffic peaks arrive using predictive forecasting
Eliminate over- and under-provisioning with demand-matched dynamic configuration
FREE for developers, forever.
Signup and connect your telemetry and billing pipelines to start tracking unit economics across your AI systems in minutes.